question = """
What is machine learning? Explain it to a five year old.
Answer within 100 words, 3 paragraphs
"""
model = "gpt-3.5-turbo"
In this notebook, we will go through different parameters in LLM that control the token generation process
- temperature
- top_p
- frequency_penalty
- presence_penalty
In each parameter, we will explore different range of values and discuss about openai’s default values and recommendations. Then in the final section we will go through some real examples to understand how these parameters affect the token generation process.
I have written two helper functions highlight_openai_response and highlight for highlighting the probabilities of the tokens generated by the model. Less probable tokens are highlighted in white and more probable tokens are highlighted in green.
import seaborn as sns
from IPython.display import HTML
import matplotlib.colors as mcolors
import numpy as np
def highlight_openai_response(response):
messages = response.choices[0].message.content
probabilities = []
for res in response.choices[0].logprobs.content:
probabilities.append(np.exp(res.logprob))
highlight(messages, probabilities)
def highlight(text, probabilities):
# Split the text into words, preserving newlines and spaces
words = []
for line in text.split("\n"):
words.extend([(word, " ") for word in line.split(" ")] + [("\n", "")])
# Remove the last element if it is a newline, added due to the split
if words[-1][0] == "\n":
words.pop()
# Ensure probabilities list matches the number of non-empty words
normalized_probs = [min(max(0, p), 1) for p in probabilities]
# Use a Seaborn color palette and map probabilities to colors
palette = sns.light_palette("green", as_cmap=True)
# Start building the HTML string using the 'pre' tag to preserve whitespace
html_string = "<pre style='font-family: inherit; white-space: pre-wrap; word-break: break-all;'>"
prob_index = 0 # Index for the current probability
for word, space in words:
if word and word != "\n": # If the element is not a space or newline
rgba_color = palette(normalized_probs[prob_index])
hex_color = mcolors.to_hex(rgba_color)
# Set the text color to black and the background color to the word's color
html_string += f"<span style='background-color: {hex_color}; color: black;'>{word}</span>"
if space:
# Set the space's background color to the word's color
html_string += f"<span style='background-color: {hex_color}; color: black;'>{space}</span>"
prob_index += 1
elif word == "\n":
# Add a newline in HTML, and reset the color for the next line
html_string += "<br>"
else:
# This case handles multiple spaces in a row
previous_hex_color = mcolors.to_hex(
palette(normalized_probs[prob_index - 1])
)
html_string += (
f"<span style='background-color: {previous_hex_color};'> </span>"
)
html_string += "</pre>" # Close the 'pre' tag
# Display the HTML string
display(HTML(html_string))highlight("Hello I am Arun", [0.9, 0.8, 0.6, 0.4])Hello I am Arun
import os
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")from openai import OpenAI, __version__
print(f"OpenAI version: {__version__}")
client = OpenAI()OpenAI version: 1.5.0seed = 42Tokens
In large language models (LLMs), tokens are the smallest units of text that the model processes and generates. They can represent individual characters, words, subwords, or even larger linguistic units, depending on the specific tokenization approach used. Tokens act as a bridge between the raw text data and the numerical representations that LLMs can work with.
In the context of OpenAI, tokens are the basic units of text processed by their language models, such as GPT-3. OpenAI employs Byte-Pair Encoding (BPE) for tokenization, which is a method initially designed for text compression. BPE identifies the most frequent pairs of characters or tokens and merges them to form new tokens, thus optimizing the tokenization process for efficiency and effectiveness in representing the text data. This approach allows the model to handle a wide range of vocabulary, including rare words or phrases, by breaking them down into subword units.

source https://platform.openai.com/tokenizer
In openai chat completion APIs, four parameter controls the token generation process. They are
- temperature
- top_p
- frequency_penalty
- presence_penalty
Temperature
In large language models, temperature is a parameter that controls the randomness of predictions by scaling the logits before applying the softmax function. A low temperature makes the model more confident and conservative, favoring more likely predictions, while a high temperature increases diversity and creativity, allowing for less probable outcomes.
Temperature adjusts the probability distribution of the next word. A higher temperature increases randomness, while a lower one makes the model more deterministic.
Purpose: It controls the level of unpredictability in the output.
The temperature adjustment equation in LaTeX format is as follows:
\[ P'(w_i) = \frac{P(w_i)^{\frac{1}{T}}}{\sum_{j=1}^{V} P(w_j)^{\frac{1}{T}}} \]
Here, \(P(w_i)\) is the original probability of the word \(w_i\), \(T\) is the temperature, \(P'(w_i)\) is the adjusted probability of the word, and \(V\) is the vocabulary size (the total number of words over which the probabilities are distributed). This equation shows how each original probability \(P(w_i)\) is raised to the power of the reciprocal of the temperature, and then normalized by dividing by the sum of all such adjusted probabilities to ensure that the adjusted probabilities sum to 1.
0.15** (1/1.9)0.3684374947235810.15** (1/0.7)0.06652540281931184import pandas as pd
# Base probabilities for 20 words
base_probabilities = [
0.19, 0.12, 0.10, 0.09, 0.08, 0.07, 0.06, 0.05, 0.04, 0.03,
0.03, 0.03, 0.02, 0.02, 0.02, 0.01, 0.01, 0.01, 0.01, 0.01
]
# Temperatures
high_temperature = 1.9
low_temperature = 0.4
# Adjusted probabilities with high temperature
adjusted_probabilities_high = [p ** (1 / high_temperature) for p in base_probabilities]
# Adjusted probabilities with low temperature
adjusted_probabilities_low = [p ** (1 / low_temperature) for p in base_probabilities]
# Normalizing the adjusted probabilities for high temperature
sum_adjusted_probabilities_high = sum(adjusted_probabilities_high)
normalized_probabilities_high = [p / sum_adjusted_probabilities_high for p in adjusted_probabilities_high]
# Normalizing the adjusted probabilities for low temperature
sum_adjusted_probabilities_low = sum(adjusted_probabilities_low)
normalized_probabilities_low = [p / sum_adjusted_probabilities_low for p in adjusted_probabilities_low]
words = [f"word{i}" for i in range(20)]
# Create a DataFrame with the words and their probabilities, adjusted for high and low temperatures
df = pd.DataFrame({
"word": words,
"base_probability": base_probabilities,
"adjusted_probability_high=1.9": adjusted_probabilities_high,
"normalized_probabilities_high=1.9": normalized_probabilities_high,
"adjusted_probability_low=0.4": adjusted_probabilities_low,
"normalized_probabilities_low=0.4": normalized_probabilities_low
})
df| word | base_probability | adjusted_probability_high=1.9 | normalized_probabilities_high=1.9 | adjusted_probability_low=0.4 | normalized_probabilities_low=0.4 | |
|---|---|---|---|---|---|---|
| 0 | word0 | 0.19 | 0.417250 | 0.111183 | 0.015736 | 0.493728 |
| 1 | word1 | 0.12 | 0.327611 | 0.087298 | 0.004988 | 0.156515 |
| 2 | word2 | 0.10 | 0.297635 | 0.079310 | 0.003162 | 0.099221 |
| 3 | word3 | 0.09 | 0.281580 | 0.075032 | 0.002430 | 0.076245 |
| 4 | word4 | 0.08 | 0.264654 | 0.070522 | 0.001810 | 0.056797 |
| 5 | word5 | 0.07 | 0.246693 | 0.065736 | 0.001296 | 0.040677 |
| 6 | word6 | 0.06 | 0.227469 | 0.060613 | 0.000882 | 0.027668 |
| 7 | word7 | 0.05 | 0.206656 | 0.055067 | 0.000559 | 0.017540 |
| 8 | word8 | 0.04 | 0.183756 | 0.048965 | 0.000320 | 0.010040 |
| 9 | word9 | 0.03 | 0.157937 | 0.042085 | 0.000156 | 0.004891 |
| 10 | word10 | 0.03 | 0.157937 | 0.042085 | 0.000156 | 0.004891 |
| 11 | word11 | 0.03 | 0.157937 | 0.042085 | 0.000156 | 0.004891 |
| 12 | word12 | 0.02 | 0.127587 | 0.033998 | 0.000057 | 0.001775 |
| 13 | word13 | 0.02 | 0.127587 | 0.033998 | 0.000057 | 0.001775 |
| 14 | word14 | 0.02 | 0.127587 | 0.033998 | 0.000057 | 0.001775 |
| 15 | word15 | 0.01 | 0.088587 | 0.023605 | 0.000010 | 0.000314 |
| 16 | word16 | 0.01 | 0.088587 | 0.023605 | 0.000010 | 0.000314 |
| 17 | word17 | 0.01 | 0.088587 | 0.023605 | 0.000010 | 0.000314 |
| 18 | word18 | 0.01 | 0.088587 | 0.023605 | 0.000010 | 0.000314 |
| 19 | word19 | 0.01 | 0.088587 | 0.023605 | 0.000010 | 0.000314 |
df["base_probability"].sum()1.0As we can see that the base probabilities decrease progressively from word0 to word19, starting at 0.19 and going down to 0.01. However, after the adjustment, the probabilities are closer to each other, indicating that the temperature scaling has made the less likely words more probable and the more probable words less dominant.
For example, word0 has its probability decreased from 0.19 to about 0.11, while word19 has its probability slightly increased from 0.01 to about 0.024. This adjustment serves to flatten the probability distribution, making the model less certain and more explorative in its word choices.
The adjusted probabilities are also normalized, as their sum should equal 1 to represent a valid probability distribution. This adjustment allows for a less deterministic and more varied text generation, which can be useful for generating more diverse and creative text outputs.
The temperature adjustment has effectively reduced the likelihood of the most probable word being selected and increased the likelihood of less probable words, thus adding variability to the text generation process.
# plot the probabilities
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(words, base_probabilities, label="Base Probabilities")
plt.plot(words, normalized_probabilities_high, label="High Temperature")
plt.plot(words, normalized_probabilities_low, label="Low Temperature")
plt.xticks(rotation=90)
plt.xlabel("Words")
plt.ylabel("Probability")
plt.legend()
plt.show()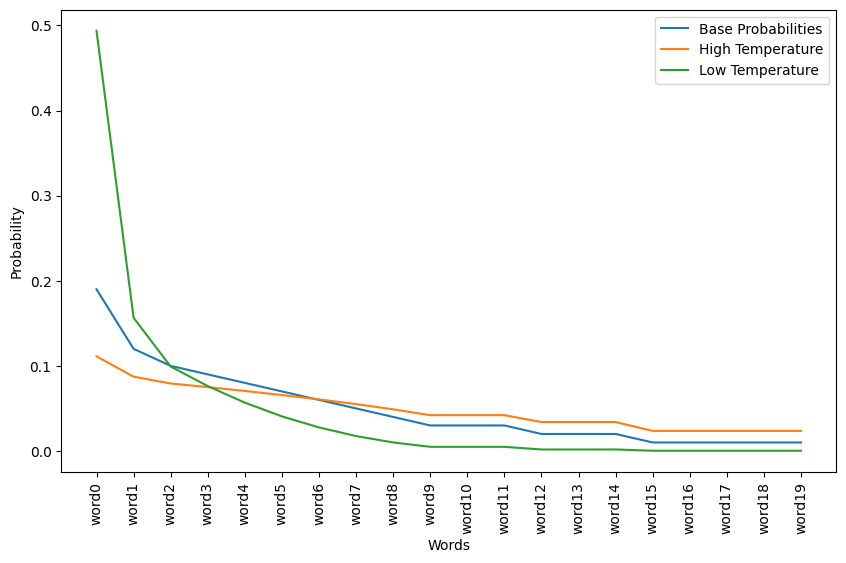
Temperature : 0( Deterministic)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=0,
seed=seed
)print(response.choices[0].message.content)Machine learning is like having a super smart robot friend that can learn things on its own. Just like how you learn new things by practicing and trying different things, machine learning is when a computer program learns from lots of examples and gets better at doing a task. For example, if you show the robot friend lots of pictures of cats and dogs, it can learn to tell the difference between them. It's like magic, but really it's just the computer using math and patterns to figure things out.response.choices[0].logprobs.content[:5] # first 5 tokens[ChatCompletionTokenLogprob(token='Machine', bytes=[77, 97, 99, 104, 105, 110, 101], logprob=-0.001537835, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' learning', bytes=[32, 108, 101, 97, 114, 110, 105, 110, 103], logprob=-0.00058532227, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' is', bytes=[32, 105, 115], logprob=-0.00044044392, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' like', bytes=[32, 108, 105, 107, 101], logprob=-0.31134152, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' having', bytes=[32, 104, 97, 118, 105, 110, 103], logprob=-1.0659788, top_logprobs=[])]probs = []import numpy as np
for res in response.choices[0].logprobs.content:
probs.append(np.exp(res.logprob))plt.hist(probs);
plt.xlabel("Probability")
plt.ylabel("Count")
plt.show()
response.system_fingerprinthighlight_openai_response(response)Machine learning is like having a super smart robot friend that can learn things on its own. Just like how you learn new things by practicing and trying different things, machine learning is when a computer program learns from lots of examples and gets better at doing a task. For example, if you show the robot friend lots of pictures of cats and dogs, it can learn to tell the difference between them. It's like magic, but really it's just the computer using math and patterns to figure things out.
High Temperature ( More Randomness)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1.6,
seed=seed
)highlight_openai_response(response)Machine learning is when computer programs can learn and improve by themselves.
Imagine you have a puzzle toy with pictures on it. At first it's all mixed up and you don't know how to make it right. When you start solving it a few times, you start getting better and can finish the puzzle faster. That's how machines work too, they start with learning puzzles and every time they make a mistake, they remember that and try not to make the same mistake again. They keep getting better and better! They can use what they have learned to help us, like find things on the internet or even drive cars.
probs = []
for res in response.choices[0].logprobs.content:
probs.append(np.exp(res.logprob))
plt.hist(probs);
plt.xlabel("Probability")
plt.ylabel("Count")
plt.show()
Temperature : 1 ( Default)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed
)highlight_openai_response(response)Machine learning is when computers learn things on their own, just like how you learn new things. Imagine you have a special toy that can remember things it sees and hears. When you show it a picture of a cat and tell it "this is a cat," the toy remembers that. Then, when you show it another picture of a cat without telling it anything, the toy can recognize that it's a cat too! This is because the toy learned from the first picture.
Machine learning is like that toy, but with big computers. They can learn from lots of pictures, sounds, and information to understand things all by themselves. The more they learn, the smarter they become. They can even help us do things like finding answers to questions, predicting what might happen next, and making decisions. It's like having a really smart friend who knows so many things!
probs = []
for res in response.choices[0].logprobs.content:
probs.append(np.exp(res.logprob))
plt.hist(probs)
plt.xlabel("Probability")
plt.ylabel("Count")
plt.show()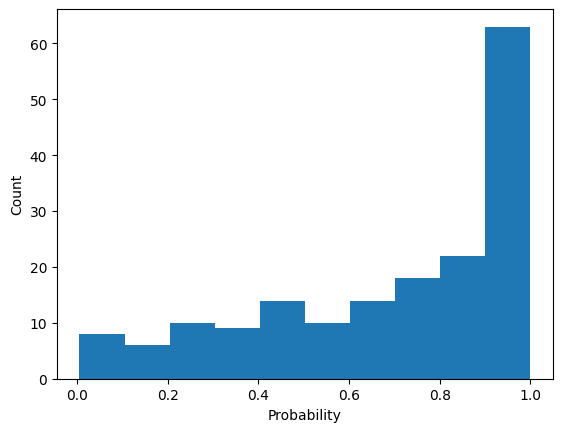
OpenAI Recommendations for Temperature
 - default is 1 - range: 0 to 2
- default is 1 - range: 0 to 2 
Top-P (Nucleus Sampling)
Top-p sampling, also known as nucleus sampling, is a technique used in large language models to control the diversity and quality of generated text. It involves selecting tokens from the most probable options, where the sum of their probabilities determines the selection.
The “top p” parameter acts as a filter, controlling how many different words or phrases the model considers when predicting the next word. The lower the value of p, the more deterministic the responses generated by the model are.
This method helps balance between diversity and high-probability words, ensuring the output is both diverse and contextually relevant.
df_p = df[['word', 'base_probability']].copy()
df_p['cumulative_probability'] = df_p['base_probability'].cumsum()
df_p| word | base_probability | cumulative_probability | |
|---|---|---|---|
| 0 | word0 | 0.19 | 0.19 |
| 1 | word1 | 0.12 | 0.31 |
| 2 | word2 | 0.10 | 0.41 |
| 3 | word3 | 0.09 | 0.50 |
| 4 | word4 | 0.08 | 0.58 |
| 5 | word5 | 0.07 | 0.65 |
| 6 | word6 | 0.06 | 0.71 |
| 7 | word7 | 0.05 | 0.76 |
| 8 | word8 | 0.04 | 0.80 |
| 9 | word9 | 0.03 | 0.83 |
| 10 | word10 | 0.03 | 0.86 |
| 11 | word11 | 0.03 | 0.89 |
| 12 | word12 | 0.02 | 0.91 |
| 13 | word13 | 0.02 | 0.93 |
| 14 | word14 | 0.02 | 0.95 |
| 15 | word15 | 0.01 | 0.96 |
| 16 | word16 | 0.01 | 0.97 |
| 17 | word17 | 0.01 | 0.98 |
| 18 | word18 | 0.01 | 0.99 |
| 19 | word19 | 0.01 | 1.00 |
df_p.style.apply(lambda x: ['background: yellow' if x.cumulative_probability <= 0.8 else '' for i in x], axis=1)| word | base_probability | cumulative_probability | |
|---|---|---|---|
| 0 | word0 | 0.190000 | 0.190000 |
| 1 | word1 | 0.120000 | 0.310000 |
| 2 | word2 | 0.100000 | 0.410000 |
| 3 | word3 | 0.090000 | 0.500000 |
| 4 | word4 | 0.080000 | 0.580000 |
| 5 | word5 | 0.070000 | 0.650000 |
| 6 | word6 | 0.060000 | 0.710000 |
| 7 | word7 | 0.050000 | 0.760000 |
| 8 | word8 | 0.040000 | 0.800000 |
| 9 | word9 | 0.030000 | 0.830000 |
| 10 | word10 | 0.030000 | 0.860000 |
| 11 | word11 | 0.030000 | 0.890000 |
| 12 | word12 | 0.020000 | 0.910000 |
| 13 | word13 | 0.020000 | 0.930000 |
| 14 | word14 | 0.020000 | 0.950000 |
| 15 | word15 | 0.010000 | 0.960000 |
| 16 | word16 | 0.010000 | 0.970000 |
| 17 | word17 | 0.010000 | 0.980000 |
| 18 | word18 | 0.010000 | 0.990000 |
| 19 | word19 | 0.010000 | 1.000000 |
df_p["base_probability"].sum()1.0High Top-P ( Includes more tokens to sample)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
top_p=1,
seed=seed
)print(response.choices[0].message.content)Machine learning is when computers learn things on their own, just like how you learn new things. Imagine you have a special toy that can remember things it sees and hears. When you show it a picture of a cat and tell it "this is a cat," the toy remembers that. Then, when you show it another picture of a cat without telling it anything, the toy can recognize that it's a cat too! This is because the toy learned from the first picture.
Machine learning is like that toy, but with big computers. They can learn from lots of pictures, sounds, and information to understand things all by themselves. The more they learn, the smarter they become. They can even help us do things like finding answers to questions, predicting what might happen next, and making decisions. It's like having a really smart friend who knows so many things!highlight_openai_response(response)Machine learning is when computers learn things on their own, just like how you learn new things. Imagine you have a special toy that can remember things it sees and hears. When you show it a picture of a cat and tell it "this is a cat," the toy remembers that. Then, when you show it another picture of a cat without telling it anything, the toy can recognize that it's a cat too! This is because the toy learned from the first picture.
Machine learning is like that toy, but with big computers. They can learn from lots of pictures, sounds, and information to understand things all by themselves. The more they learn, the smarter they become. They can even help us do things like finding answers to questions, predicting what might happen next, and making decisions. It's like having a really smart friend who knows so many things!
response.choices[0].logprobs.content[:5] # first 5 tokens[ChatCompletionTokenLogprob(token='Machine', bytes=[77, 97, 99, 104, 105, 110, 101], logprob=-0.0015492603, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' learning', bytes=[32, 108, 101, 97, 114, 110, 105, 110, 103], logprob=-0.0005857991, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' is', bytes=[32, 105, 115], logprob=-0.00047642877, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' when', bytes=[32, 119, 104, 101, 110], logprob=-1.7854097, top_logprobs=[]),
ChatCompletionTokenLogprob(token=' computers', bytes=[32, 99, 111, 109, 112, 117, 116, 101, 114, 115], logprob=-0.25018257, top_logprobs=[])]probs = []
for res in response.choices[0].logprobs.content:
probs.append(np.exp(res.logprob))
plt.hist(probs);
plt.xlabel("Probability")
plt.ylabel("Count")
plt.show()
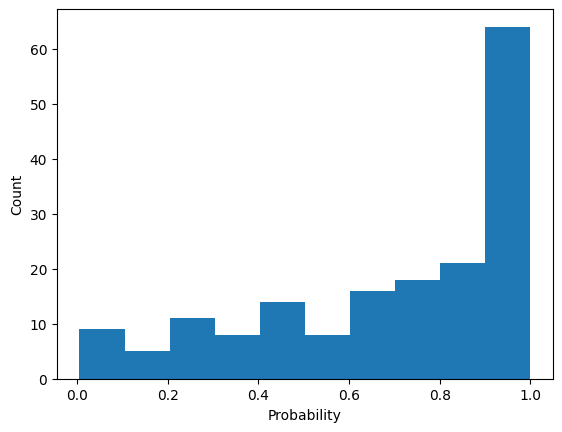
Low Top-P ( More Deterministic)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
top_p=0.2,
seed=seed
)highlight_openai_response(response)Machine learning is like having a super smart robot friend that can learn things on its own. Just like how you learn new things by practicing and trying different things, machine learning is when a computer program learns from lots of examples and gets better at doing a task. For example, if you show the robot friend lots of pictures of cats and dogs, it can learn to tell the difference between them. It's like magic, but really it's just the computer using math and patterns to figure things out.
probs = []
for res in response.choices[0].logprobs.content:
probs.append(np.exp(res.logprob))
plt.hist(probs);
plt.xlabel("Probability")
plt.ylabel("Count")
plt.show()
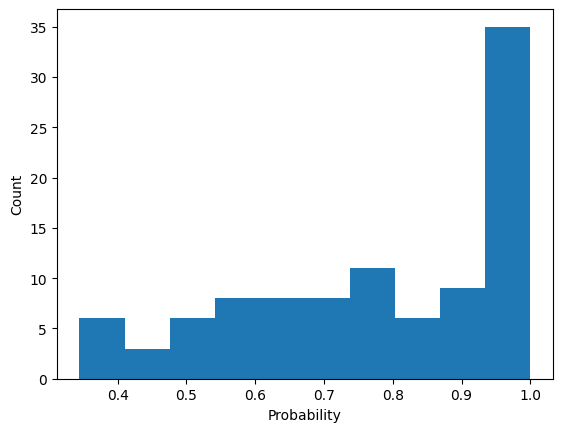
OpenAI Recommendations for Top-P

Interactions between Temperature and Top-P
Let’s experiment the interactions between temperature and top-p
- High Temperature and High Top-P
- High Temperature and Low Top-P
- Low Temperature and High Top-P
- Low Temperature and Low Top-P
High Temperature, High Top-P
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
top_p=1,
temperature=1.6,
seed=seed
)
highlight_openai_response(response)Machine learning is when computer programs can learn and improve by themselves.
Imagine you have a puzzle toy with pictures on it. At first it's all mixed up and you don't know how to make it right. When you start solving it a few times, you start getting better and can finish the puzzle faster.
Machine learning works a bit like that. It's like a really smart program that learns from doing things over and over again. It gets more and more powerful, by learning from its own experiences! So just like you, the computer program gets better and better at solving the problems it faces. Isn’t that amazing?!
High Temperature, Low Top-P
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
top_p=0.2,
temperature=1.5,
seed=seed
)
highlight_openai_response(response)Machine learning is like having a super smart robot friend that can learn things on its own. Just like how you learn new things by practicing and trying different things, machine learning is when a computer program learns from lots of examples and gets better at doing a task. For example, if you show the robot friend lots of pictures of cats and dogs, it can learn to tell the difference between them. It's like magic, but really it's just the computer using math and patterns to figure things out.
Low Temperature, High Top-P
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
top_p=1,
temperature=0.2,
seed=seed
)
highlight_openai_response(response)Machine learning is like having a super smart robot friend that can learn things on its own. It's like when you play a game and get better each time because you remember what you did before. But instead of a game, the robot friend learns from lots of information and figures out patterns and rules. Then it can use what it learned to make predictions or do tasks without being told exactly what to do. It's like having a really clever friend who can help you with all sorts of things!
Low Temperature, Low Top-P
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
top_p=0.2,
temperature=0.2,
seed=seed
)
highlight_openai_response(response)Machine learning is like having a super smart robot friend that can learn things on its own. Just like how you learn new things by practicing and trying different things, machine learning is when a computer program learns from lots of examples and gets better at doing a task. For example, if you show the robot friend lots of pictures of cats and dogs, it can learn to tell the difference between them. It's like magic, but really it's just a computer using math to learn and make decisions.

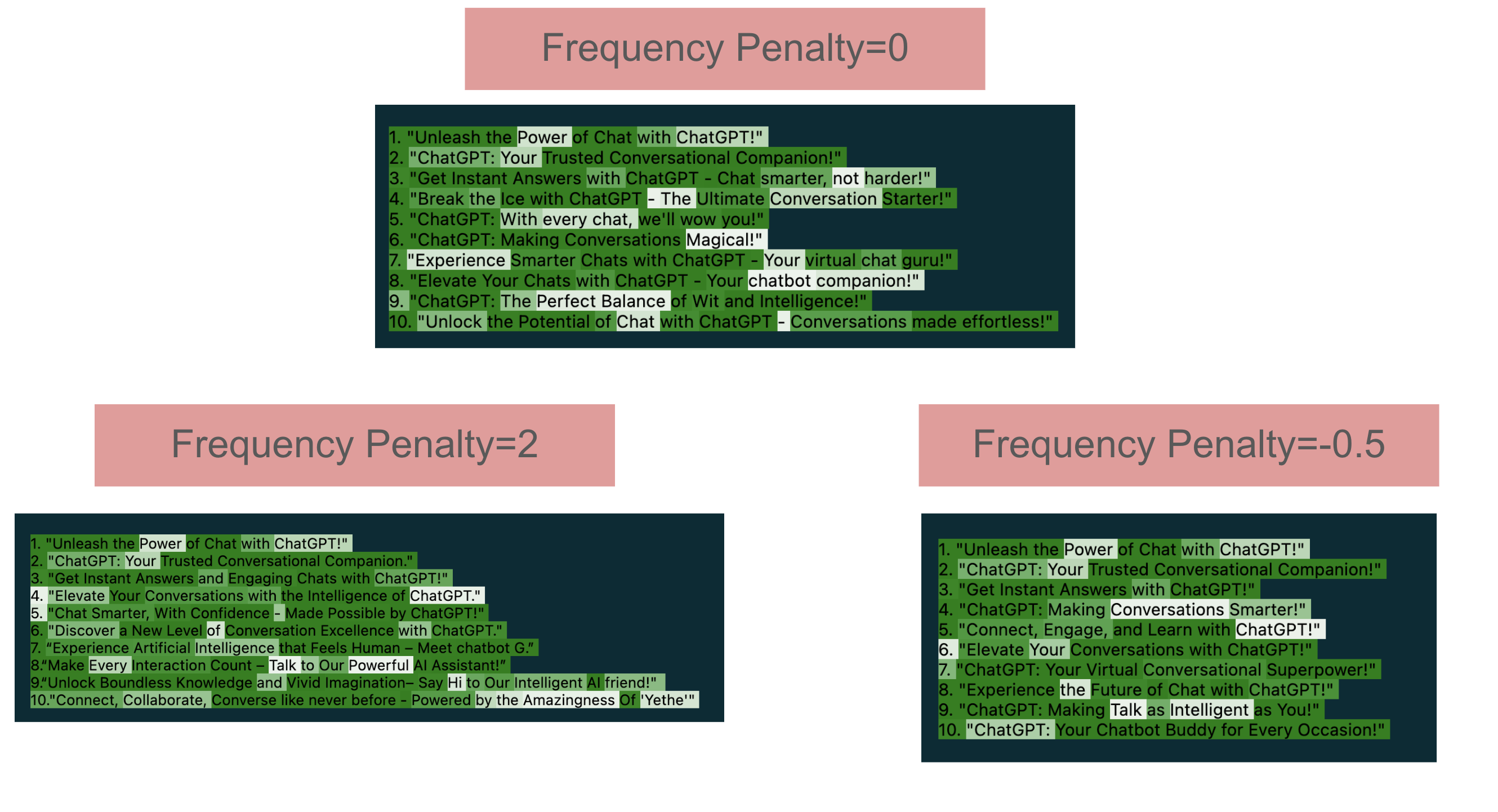
Frequency Penalty
Frequency Penalty is used to reduce the likelihood of a token being selected again if it has already appeared in the generated text.
It ranges from -2.0 to 2.0, where positive values discourage repetition by penalizing tokens that occur frequently, and negative values can increase the likelihood of repetition. This helps control the diversity of the generated content and prevent verbatim repetition.

In the above example, we can see recommendations such as National Park appeared twice in the generated text. We can use frequency penalty to reduce the likelihood of a token being selected again if it has already appeared in the generated text.
question = """
Write 10 slogans for ChatGPT
"""
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion!"
3. "Get Instant Answers with ChatGPT - Chat smarter, not harder!"
4. "Break the Ice with ChatGPT - The Ultimate Conversation Starter!"
5. "ChatGPT: With every chat, we'll wow you!"
6. "ChatGPT: Making Conversations Magical!"
7. "Experience Smarter Chats with ChatGPT - Your virtual chat guru!"
8. "Elevate Your Chats with ChatGPT - Your chatbot companion!"
9. "ChatGPT: The Perfect Balance of Wit and Intelligence!"
10. "Unlock the Potential of Chat with ChatGPT - Conversations made effortless!"
High Frequency Penalty
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed,
frequency_penalty=2
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion."
3. "Get Instant Answers and Engaging Chats with ChatGPT!"
4. "Elevate Your Conversations with the Intelligence of ChatGPT."
5. "Chat Smarter, With Confidence - Made Possible by ChatGPT!"
6. "Discover a New Level of Conversation Excellence with ChatGPT."
7. “Experience Artificial Intelligence that Feels Human – Meet chatbot G.”
8.“Make Every Interaction Count – Talk to Our Powerful AI Assistant!”
9.“Unlock Boundless Knowledge and Vivid Imagination– Say Hi to Our Intelligent AI friend!"
10."Connect, Collaborate, Converse like never before - Powered by the Amazingness Of 'Yethe'"
Low Frequency Penalty
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed,
frequency_penalty=-0.5
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion!"
3. "Get Instant Answers with ChatGPT!"
4. "ChatGPT: Making Conversations Smarter!"
5. "Connect, Engage, and Learn with ChatGPT!"
6. "Elevate Your Conversations with ChatGPT!"
7. "ChatGPT: Your Virtual Conversational Superpower!"
8. "Experience the Future of Chat with ChatGPT!"
9. "ChatGPT: Making Talk as Intelligent as You!"
10. "ChatGPT: Your Chatbot Buddy for Every Occasion!"

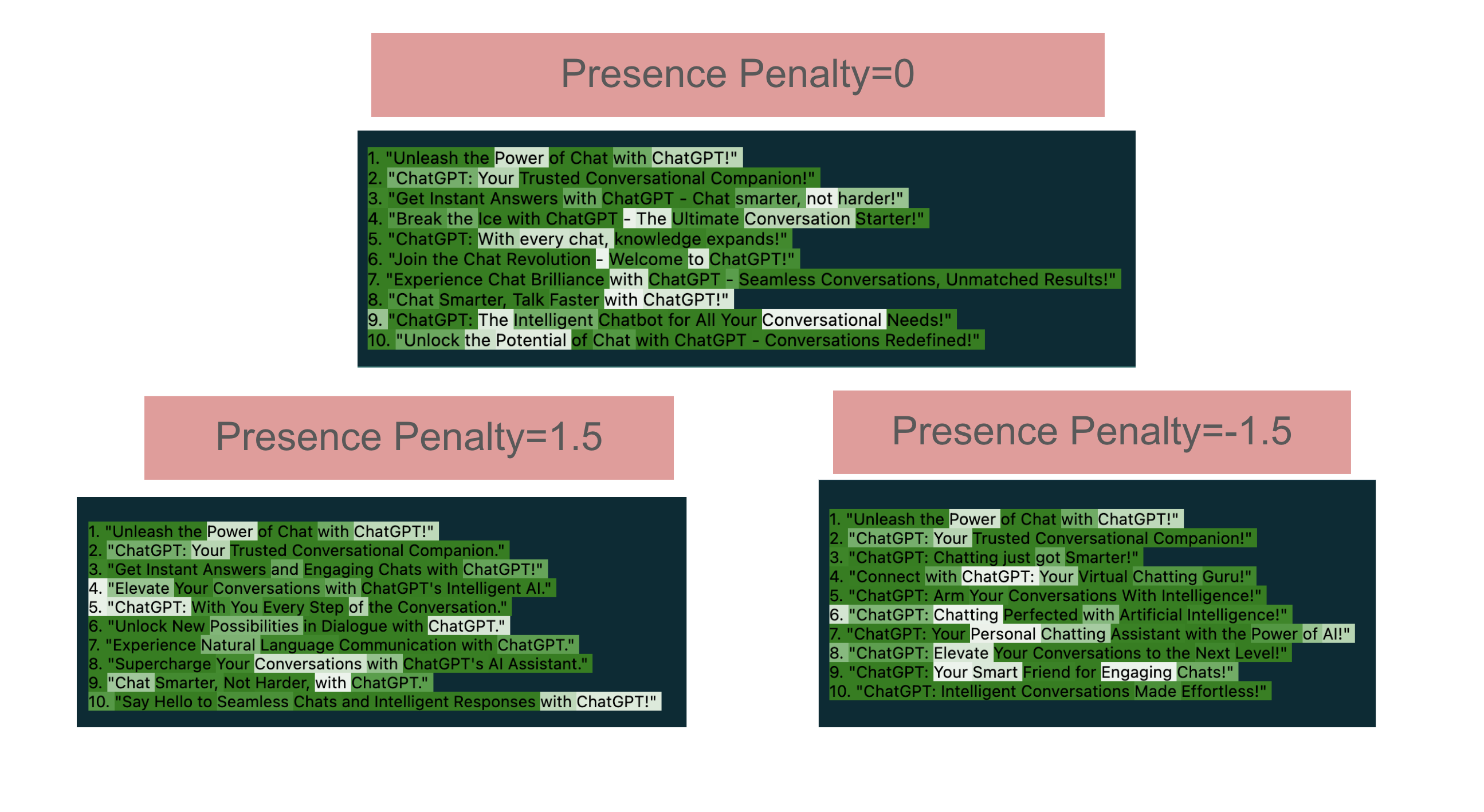
Presence Penalty
Presence Penalty is a parameter that influences the generation of new content by penalizing tokens that have already appeared in the text. It ranges from -2.0 to 2.0, where positive values discourage repetition and encourage the model to introduce new topics, while negative values do the opposite. This penalty is applied as a one-time, additive contribution to tokens that have been used at least once, helping to ensure more diverse and creative outputs
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion!"
3. "Get Instant Answers with ChatGPT - Chat smarter, not harder!"
4. "Break the Ice with ChatGPT - The Ultimate Conversation Starter!"
5. "ChatGPT: With every chat, knowledge expands!"
6. "Join the Chat Revolution - Welcome to ChatGPT!"
7. "Experience Chat Brilliance with ChatGPT - Seamless Conversations, Unmatched Results!"
8. "Chat Smarter, Talk Faster with ChatGPT!"
9. "ChatGPT: The Intelligent Chatbot for All Your Conversational Needs!"
10. "Unlock the Potential of Chat with ChatGPT - Conversations Redefined!"
High Presence Penalty
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed,
presence_penalty=1.5
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion."
3. "Get Instant Answers and Engaging Chats with ChatGPT!"
4. "Elevate Your Conversations with ChatGPT's Intelligent AI."
5. "ChatGPT: With You Every Step of the Conversation."
6. "Unlock New Possibilities in Dialogue with ChatGPT."
7. "Experience Natural Language Communication with ChatGPT."
8. "Supercharge Your Conversations with ChatGPT's AI Assistant."
9. "Chat Smarter, Not Harder, with ChatGPT."
10. "Say Hello to Seamless Chats and Intelligent Responses with ChatGPT!"
Low Presence Penalty
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed,
presence_penalty=-2
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion!"
3. "ChatGPT: Chatting just got Smarter!"
4. "Connect with ChatGPT: Your Virtual Chatting Guru!"
5. "ChatGPT: Arm Your Conversations With Intelligence!"
6. "ChatGPT: Chatting Perfected with Artificial Intelligence!"
7. "ChatGPT: Your Personal Chatting Assistant with the Power of AI!"
8. "ChatGPT: Elevate Your Conversations to the Next Level!"
9. "ChatGPT: Your Smart Friend for Engaging Chats!"
10. "ChatGPT: Intelligent Conversations Made Effortless!"

Interaction between Frequency Penalty and Presence Penalty
High Frequency Penalty and High Presence Penalty
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed,
presence_penalty=1.8,
frequency_penalty=1.8
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion."
3. "Get Instant Answers and Engaging Chats with ChatGPT!"
4. "Elevate Your Conversations with AI-Powered ChatGPT."
5. "Let's Talk! With Dynamic Dialogue Made Easy by ChatGPT."
6. "Discover Smarter, More Natural Chats Using ChatGPT."
7. "Unlock a World of Seamless Communication with ChatGPT."
8 ."Experience Human-Like Interactions using our Advanced Assistant -Chat Gpt"
9 ."Your Virtual Conversation Buddy – Get Talking With Chat Gpt Now ! "
10 ."Revolutionize Your Conversations w
Low Frequency Penalty and Low Presence Penalty
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question}
],
logprobs=True,
temperature=1,
seed=seed,
presence_penalty=-0.5,
frequency_penalty=-0.5
)
highlight_openai_response(response)1. "Unleash the Power of Chat with ChatGPT!"
2. "ChatGPT: Your Trusted Conversational Companion!"
3. "ChatGPT: Chatting just got Smarter!"
4. "Connect with ChatGPT: Chatting with Intelligence!"
5. "ChatGPT: Revolutionizing Chatting, One Conversation at a Time!"
6. "ChatGPT: Your Virtual Chatting Expert!"
7. "ChatGPT: Chatting with Artificial Intelligence that Feels Human!"
8. "ChatGPT: Chatting made Easy, Chatting made Powerful!"
9. "ChatGPT: Chatting with the Next Level of Chatbot Technology!"
10. "ChatGPT: Chatting. Redefined. "
Practical Use Cases
Industry 1: Creative Writing (e.g., Novels, Short Stories)
- Temperature: Set to 0.8-0.9. Higher temperature encourages more creative and unexpected turns of phrase, enhancing the storytelling with originality.
- Top P (Nucleus Sampling): Set around 0.9. Allows for a good range of probable words while still fostering creativity, which is vital in creative writing.
- Frequency Penalty: Set to a moderate value (e.g., 0.5). Helps avoid excessive repetition of words/phrases, maintaining a fresh and engaging narrative.
- Presence Penalty: Set to a lower value (e.g., 0.3-0.4). Encourages some repetition of key themes or phrases, which can be a powerful tool in storytelling.
Industry 2: Customer Support (e.g., Chatbots for Service Queries)
- Temperature: Set lower, around 0.3-0.4. Ensures more predictable and relevant responses, crucial for accurate customer support.
- Top P (Nucleus Sampling): Set around 0.8. Balances the need for coherent, relevant responses while allowing for some variability to better match customer queries.
- Frequency Penalty: Moderate to high (e.g., 0.6-0.8). In customer support, avoiding repetitive phrases can enhance clarity and professionalism in responses.
- Presence Penalty: Moderate (e.g., 0.5). Helps ensure a variety of information is provided, which can be crucial in addressing diverse customer queries comprehensively.
Explanation:
- Creative Writing: The settings are designed to maximize creativity and originality, ensuring a rich and engaging narrative.
- Customer Support: The focus here is on accuracy, relevance, and clarity in responses, which are essential in a customer support context.